


Philip Marchenko
Machine Learning Engineer
Senior Machine Learning Engineer & Researcher at Altris AI
Reading time
15 min read
According to the World Health Organization (WHO), artificial intelligence (AI) and machine learning (ML) will improve health outcomes by 2025. There are numerous digital technologies that shape the health of the future, yet AI and machine learning in ophthalmology and medical image analysis look like one of the most promising innovations.
The healthcare industry produces millions of medical images: MRI, CT, OCT, images from the lab, etc. The right diagnosis depends on the accuracy of the analysis by the specialists. Today AI can back up any medical specialist in medical image analysis: providing confidence and much-needed second opinion.
Try Altris AI for free
Check how artificial intelligence assists in OCT interpretation
Altris AI team decided to improve medical image analysis for just one type of medical image: Optical Coherence Tomography scans of the retina. To do it, the Altris AI team collected thousands of OCT scans and graphically labeled them, defining more than 100 pathologies and pathological signs. Watch the video to discover more features of Altris AI platform.
Then all this data was fed into the AI model. Further, I will tell how exactly we train the AI model of Altris AI so that it can detect more than 100 pathologies with 91% accuracy, but first, let’s discuss why it is important for the healthcare industry.
Why are automation and machine learning in ophthalmology important?
Due to the delicate anatomy of the eye, its treatment carries a high risk of complications. Sometimes these complications can be the result of a medical error by an eye care specialist. But how often?
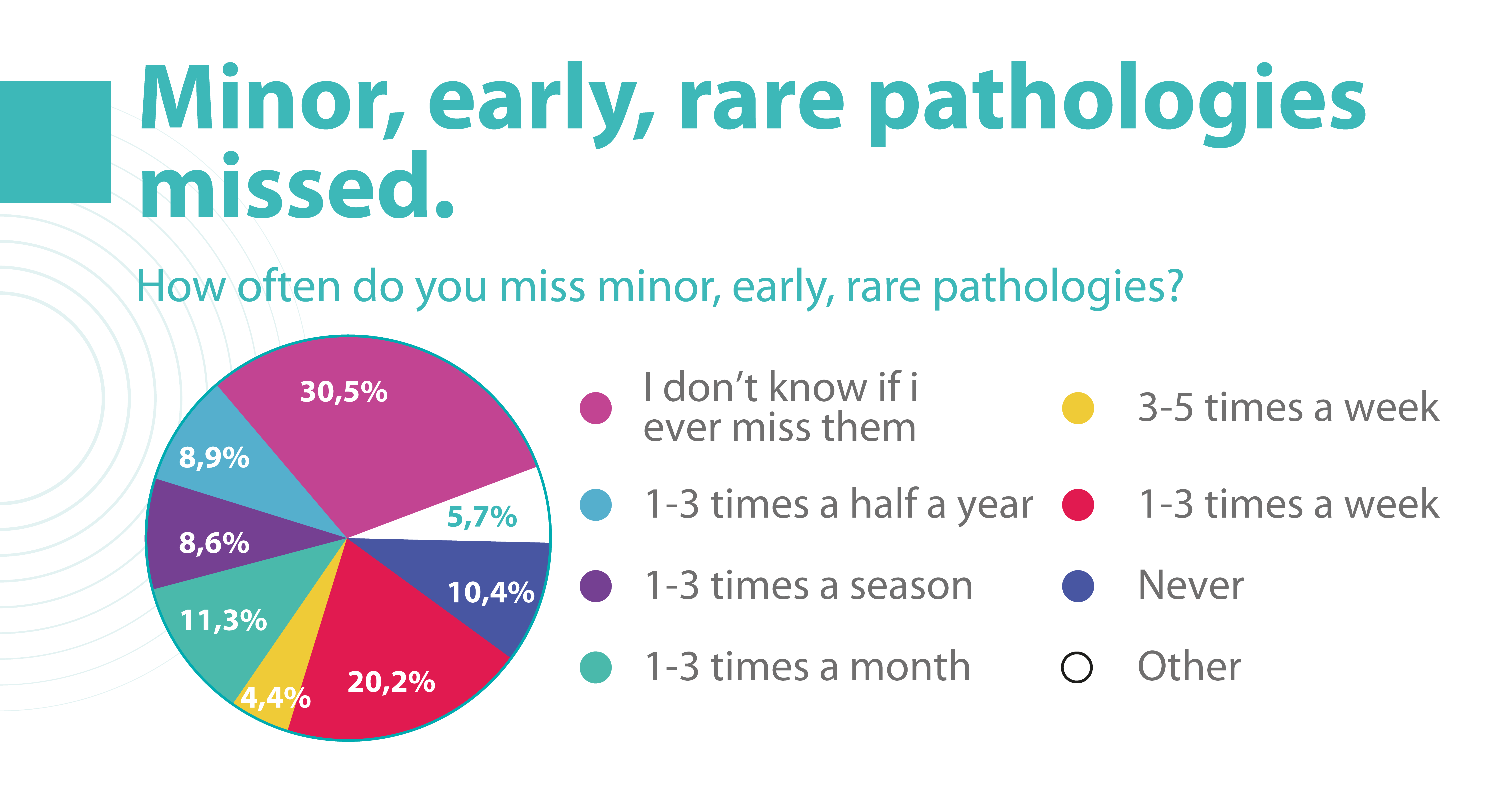
According to the Altris team research, 20.2% of eye care practitioners miss minor, early, and rare pathologies on OCT scans 1- 3 times a week, and 4.4% miss them 3-5 times a week. But the worst thing is that 30.5% of ophthalmologists and optometrists are not even sure if they are missing any pathology at all.
Some medical errors may be minor, but some may cause significant harm to patients. Such medical errors can lead to medical malpractice lawsuits. That is why most ophthalmic clinics consider implementing AI to double-check the diagnosis of the ophthalmologist.
Besides, different tools of machine learning in ophthalmology have a high level of accuracy and can provide eye care specialists with a second opinion.
How to reach a high level of accuracy?
It is almost always necessary to conduct many experiments to achieve a high level of model accuracy (in the case of Altris AI, it is 91%). It is often done with the help of a machine learning pipeline.
High level of ML pipeline accuracy
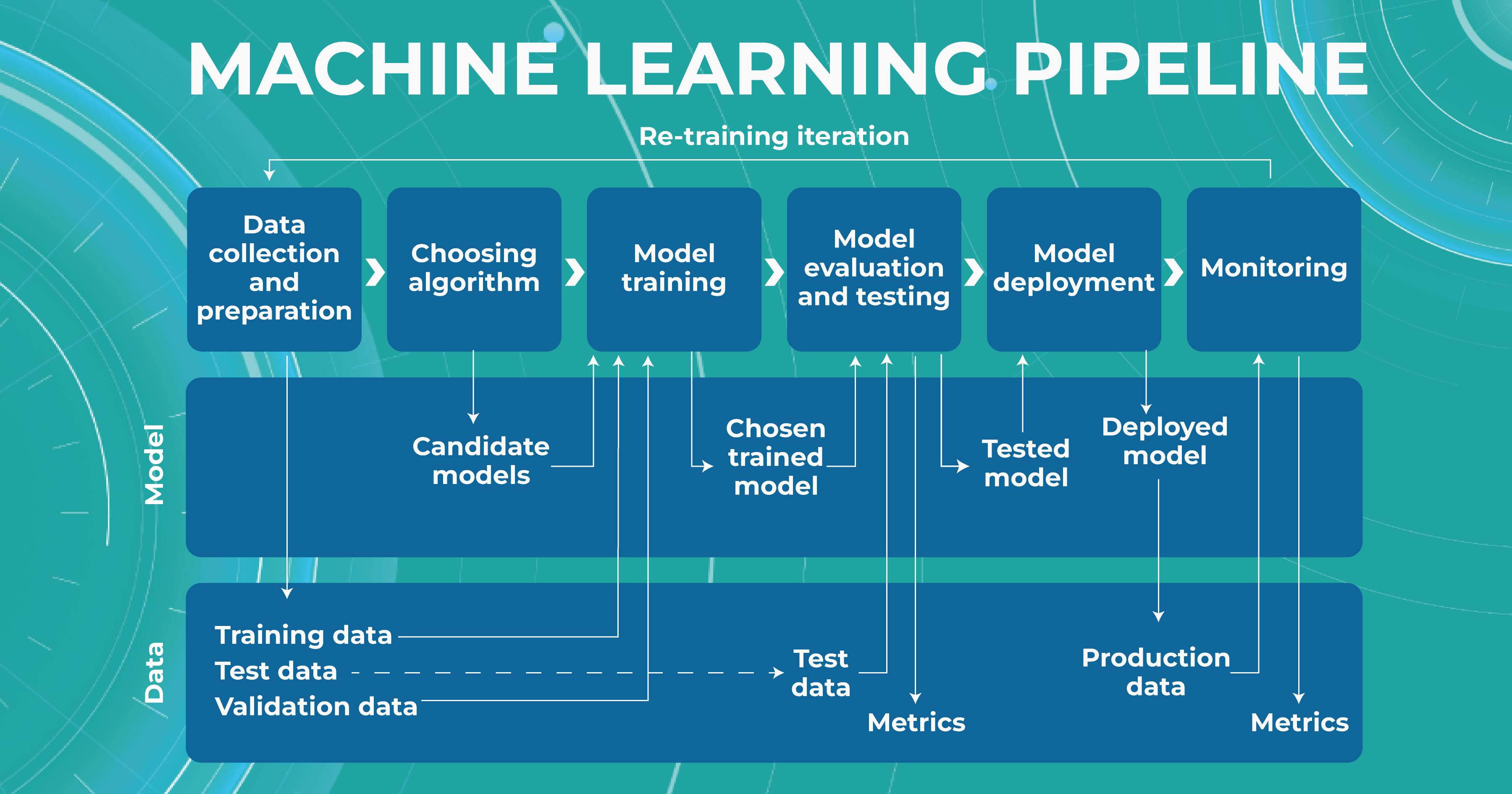
The machine learning pipeline is programmed by a team of engineers to perform certain steps automatically. It systematically trains and evaluates models, monitors experiments, and works with datasets.
-
- ML and Medical teams collect, annotate and preprocess data. It’s crucial to ensure the data quality is at its highest level because the model’s quality heavily depends on it. To do this, the teams developed a process and annotation guideline, which ensures that the number of errors in the annotation is minimized.
- ML team chooses the appropriate approach (model) depending on the collected data and the tasks. Each team member is well-versed in the most modern and high-quality approaches that solve emerging tasks.
- The selected model is trained on the annotated data.
- In the model evaluating and testing stage, we develop tests aimed at helping us understand whether the model is trained properly to perform the needed tasks.
- After the ML team is satisfied with the result, we deploy the model, which means the model is ready for production.
- While the model is running in production, we monitor its performance to ensure everything goes well.
This workflow allows engineers to continuously fine-tune existing models alongside constant performance evaluations. The most significant advantage of this process is that it can be automated with the help of available tools.
Try Altris AI for free
Check how artificial intelligence assists in OCT interpretation
What tasks does machine learning in ophthalmology have?
Within the Altris AI platform, we solve 2 main tasks: segmentation and classification of OCT scans.
Classification task
Classification is the task of determining which category a particular object belongs to. We assign each pathology to a certain class of pathologies (for example, glaucoma class).
Segmentation task
The image segmentation problem can be stated as the division of an image into regions that separate different objects from each other, and from the background.
Key metrics of Altris ML pipeline
When discussing classification and segmentation metrics in medical imaging machine learning, it is essential to mention the Confusion matrix (CM). CM is a visualization of our performance, which helps us understand whether the model is performing well in terms of predicted and real data. For a better explanation, let’s take a look at the picture.
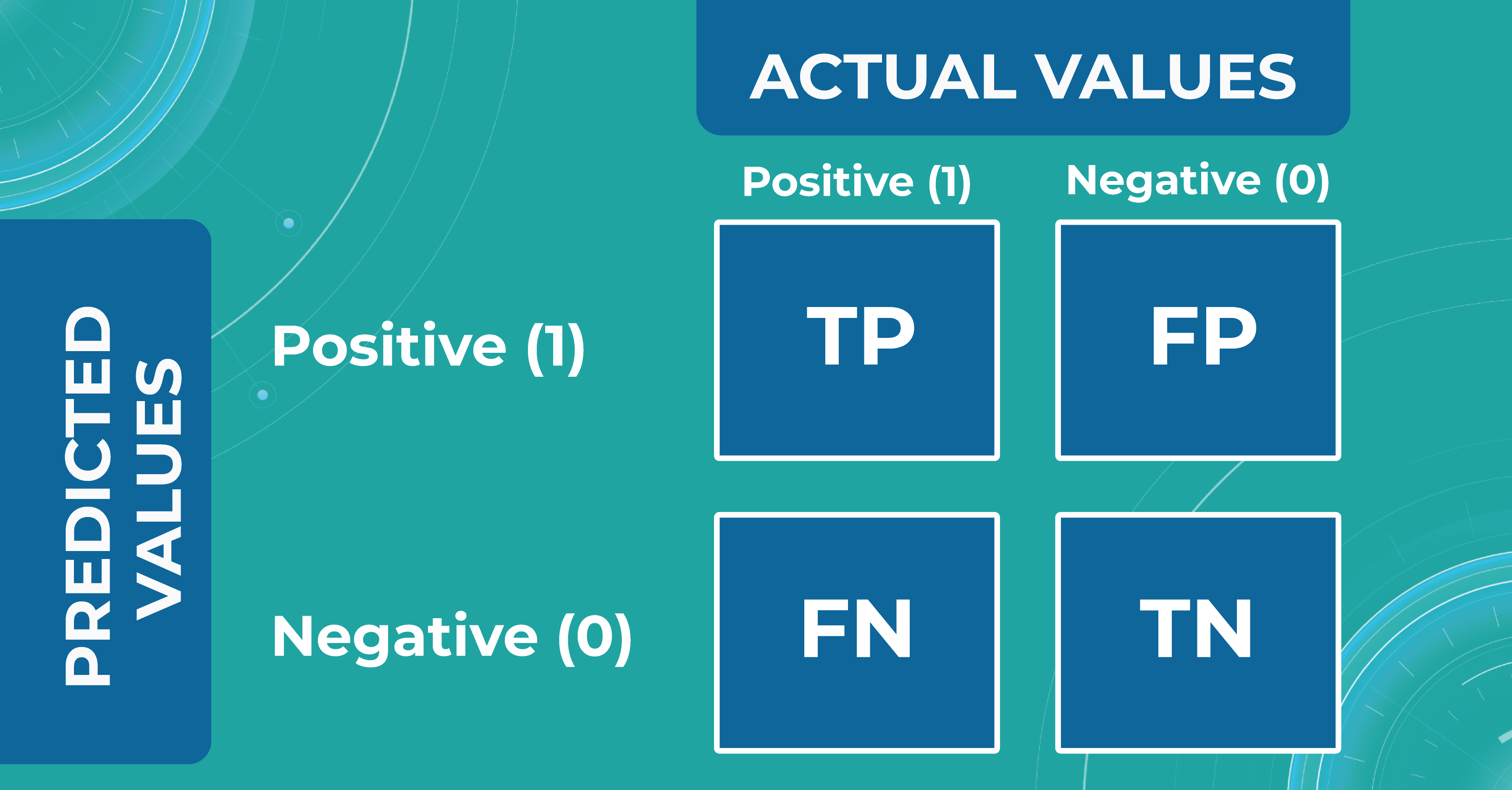
Let’s consider 4 possible outcomes from model predictions. Say we need to create a classifier to diagnose or predict if a patient has a disease (positive / 1 or TRUE) or not (negative/ 0 or FALSE). In such a case, the model can predict “yes” or “no”, and we can have an actual “yes” or “no”. Based on this, we can get 4 categories of results:
- TP — true positive. The patient that actually has a disease has been diagnosed with this disease. A class was predicted to be true, and it is actually true.
- TN — true negative. The patient is actually healthy and has been diagnosed as healthy. A class was predicted to be false, and it is actually false.
- FP — false positive (type 1 error). The patient that is actually healthy has been diagnosed as having a disease. A class was predicted to be true, but it is actually false.
- FN — false negative (type 2 error). The patient that actually has a disease has been diagnosed as healthy. A class was predicted to be false, but it is actually true.
With the help of the confusion matrix, our ML engineers get specific metrics needed to train our medical imaging machine learning model properly. We discuss each metric in more detail in the following paragraphs.
Classification metrics
- Accuracy
To find out how many of our predictions were correct, we divide the number of correct predictions by the total.

While being intuitive, the accuracy metric heavily relies on data specifics. If the dataset is imbalanced (the classes in a dataset are presented unevenly), we won’t get trustful results.
For example, if we have a training dataset with 98% samples of class A (healthy patients) and only 2% samples of class B (sick patients). The medical imaging machine learning model can easily give you 98% training accuracy by predicting that every patient is healthy, even if they have a disease. Such results may have destructive consequences as people won’t get needed medical treatment.
- Precision
Precision shows what proportion out of all positive predictions was correct.

Precision metric helps us in cases when we need to avoid False Negatives but can’t ignore False Positives. A typical example of this is a spam detector model. As engineers, we would be satisfied if the model sent a couple of spam letters to the inbox. However, sending an important non-spam letter to the spam folder (False Positive) is much worse.
- Sensitivity/Recall
Recall shows how many of all really sick patients we predicted and diagnosed correctly. It is a proportion of correctly positive predictions out of all positives.
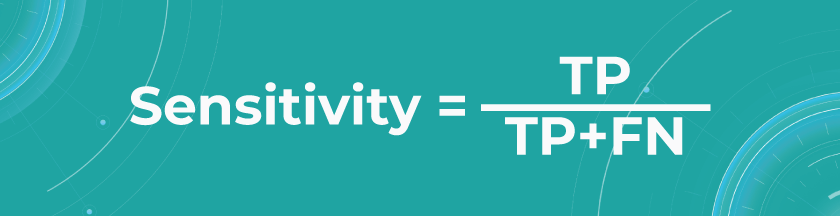
In our case, you want to find all sick people, so it would not be so critical if the model diagnoses some healthy people as unhealthy. They would probably be sent to take some extra tests, which is annoying but not critical. But it’s much worse if the model diagnoses sick people as healthy and leaves them without treatment.
The sensitivity of Altris AI is 92,51%
- Specificity
The specificity shows how many of all healthy patients we predicted correctly. It is the proportion of actual negatives that the medical imaging machine learning model has correctly identified as such out of all negatives.
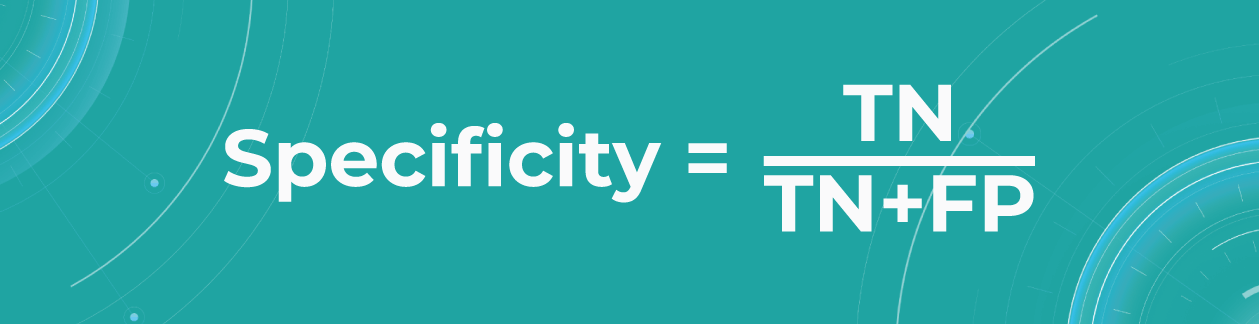
Specificity should be the metric of choice if you must cover all true negatives and you can’t tolerate any false positives as a result. For example, we’re making a fraud detector model in which all people whose credit card has been flagged as fraudulent (positive) will immediately go to jail. You don’t want to put innocent people behind bars, meaning false positives here are unacceptable.
The specificity of Altris AI is 99,80%
Segmentation metrics
Segmentation also can be thought of as a classification task. For each pixel, we make predictions about whether it is a certain object or not. Therefore, we can talk about Accuracy, Precision, Recall, and Specificity in terms of segmentation.
Let’s say we have a Ground Truth (what is really an object) and a Segmented (what the model predicted). The intersection in the picture below is the correct operation of the medical imaging machine learning model. All that is the difference (FN and FP) is the incorrect operation of the model. True negative (TN) is everything the model did not mark in this case.
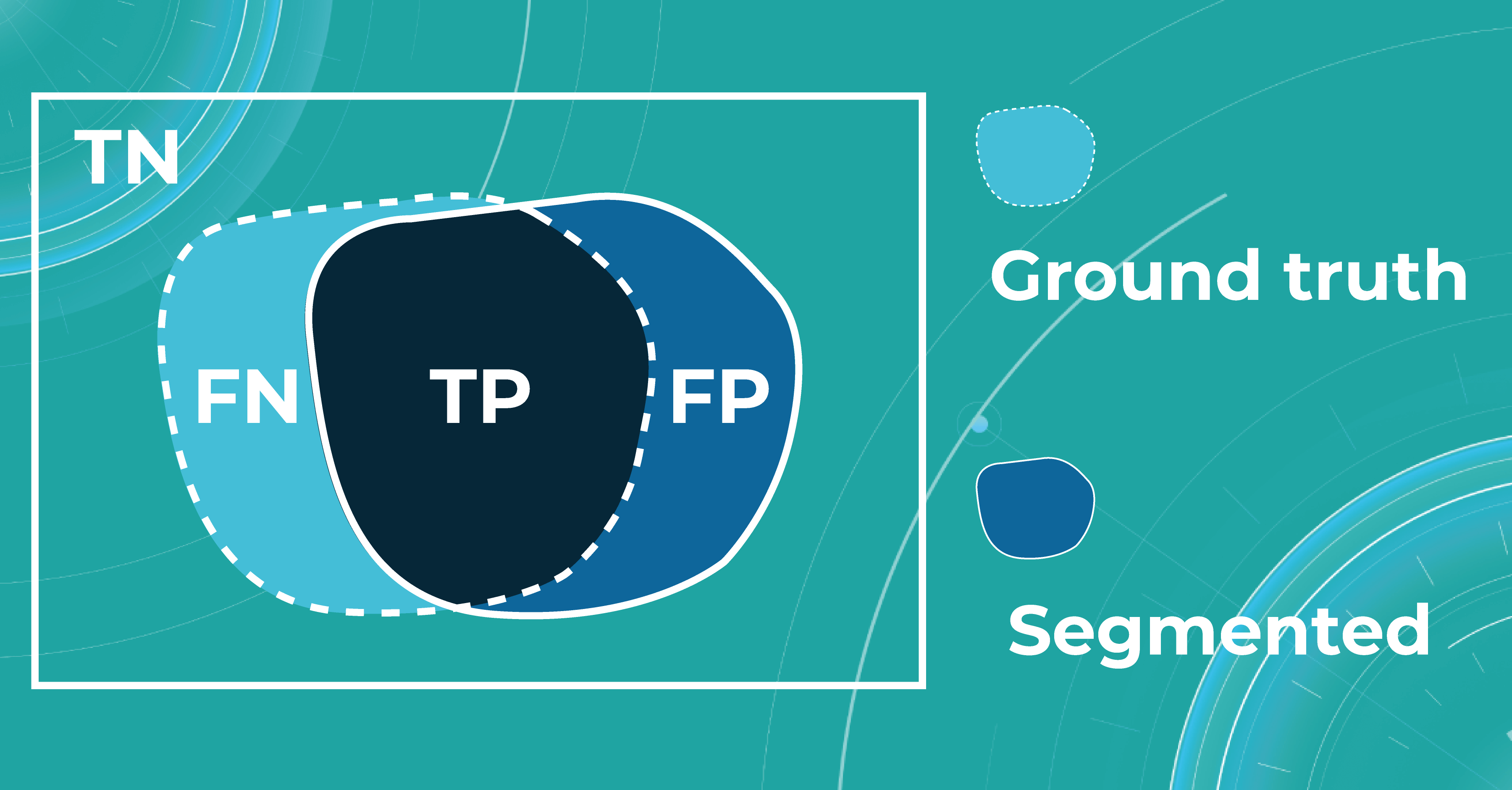
Quite often, even after looking at such metrics, the problem of non-symmetricity remains in the segmentation tasks. For example, if we consider a tiny object, the Accuracy metric doesn’t work. Therefore, segmentation tasks also refer to additional metrics that allow taking into account the size of the object of the overall quality assessment. Let’s look at additional metrics in more detail.
- Intersection over Union (IoU)/Jaccard
Intersection over Union is an evaluation metric used to measure segmentation accuracy on a particular image. This metric is considered quite simple — the intersection zone is divided by the union of Ground Truth and Segmented.
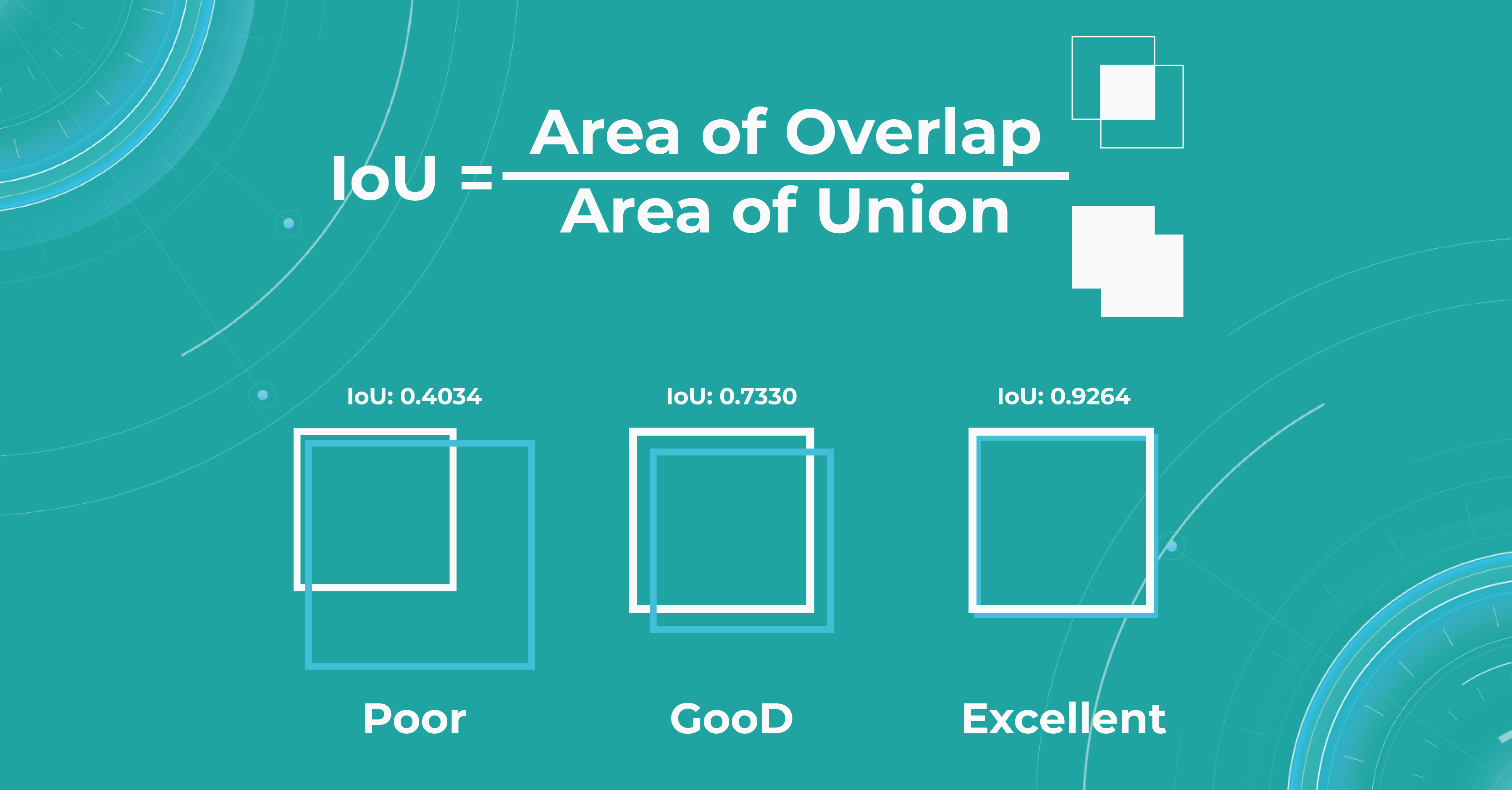
Sometimes we get such results, like if the object was determined to be very large, but in fact, we see that it is small. Then the metric will be low, and vice versa. If the masks are approximately equal to each other, everything works correctly, and the metric will be high.
- Dice score/F1
The dice coefficient is 2 times the area of overlap divided by the total number of pixels in both images.
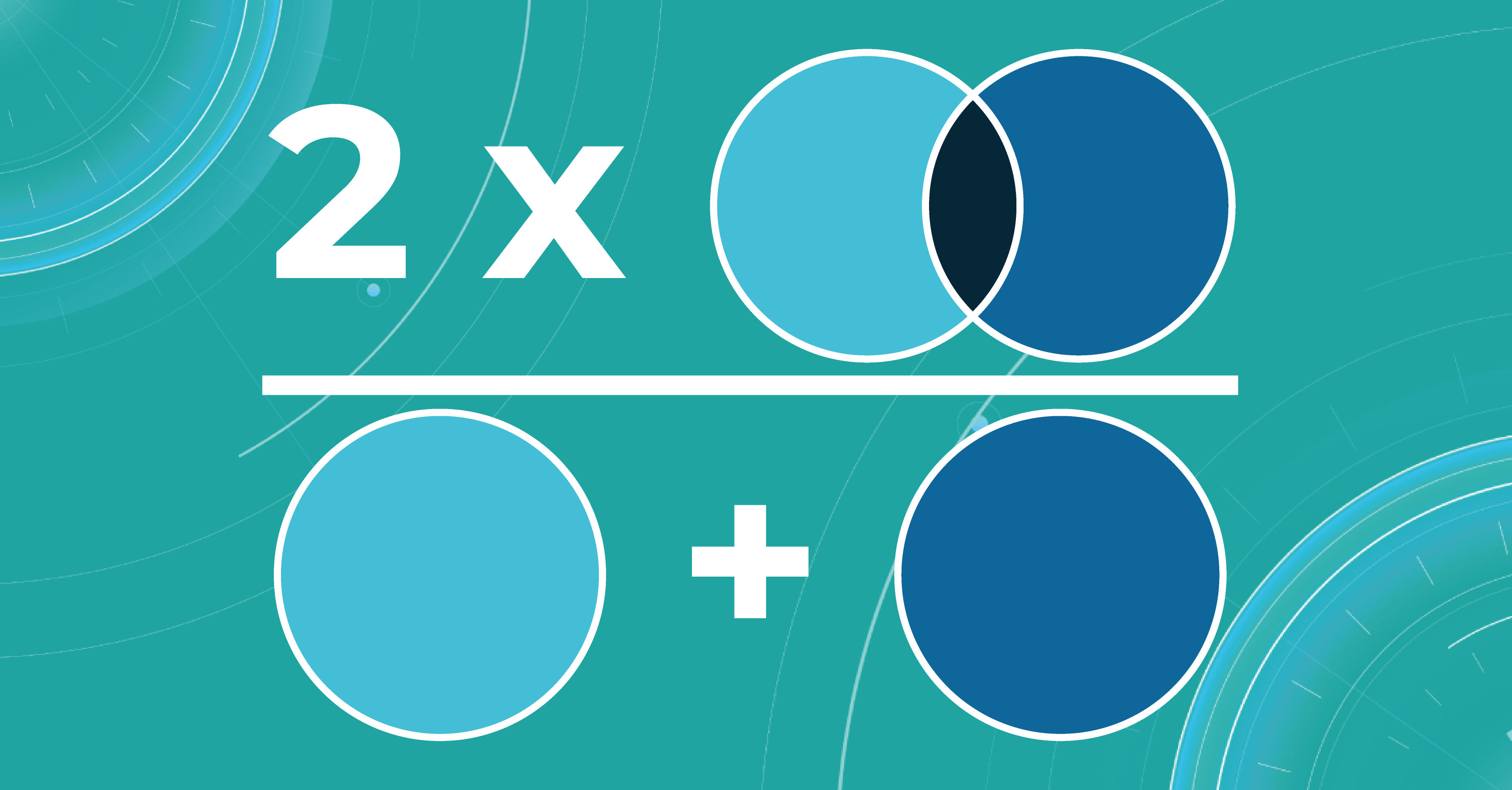
This metric is a slight modification of the previous one. The difference is that, in this case, we take the intersection area twice.
Calculating scores over dataset
We calculate the metrics described above for each scan. In order to count them over the entire dataset, we take each picture in this dataset, segment it, calculate the metric, and then take the average value of the metrics on each image.
What is model validation in ML?
In addition to evaluating the metrics, we also need to design the model validation procedure suitable for a specific task.
When we have determined the metric that suits the task of machine learning for medical image analysis, we also need to understand what data to use for calculation. It will be wrong to calculate the metric on the training data because the model has already seen it. This means that we will not check the ability of the model to generalize in any way. Thus, we need a specific test dataset so that we can carry out quality control according to the selected metrics.
The main tasks of the model validation are:
- To provide an unbiased estimation of the accuracy that the model can achieve
- To check whether the model is not overfitted
Picking the correct model validation process is critical to guarantee the exactness of the validation method. In addition, there is no single suitable validation method for machine learning in ophthalmology — each task requires different validation. Engineers separately examine each task to see if data has leaked from the train dataset to the test dataset because this may lead to an overly optimistic estimate of the metrics.
For example, we can take OCT images in different resolutions. We may need a higher image resolution for some diseases. If the medical imaging machine learning model overfits at the resolution of this OCT, it will be called a leak because the model should behave the same at any resolution.
Overfitting and underfitting
The model also has such an important property as a generalization. If the model did not see some data during training, it should not be difficult for the model to determine which class a certain image belongs to.
At this stage, engineers may have two problems that they need to solve. The first problem is overfitting. When the model remembers the training data too well, we lose the ability to make correct predictions. The picture below illustrates this problem. The chart in the middle is a good fit when the model is general enough and has a positive trend, and the trend is well-learned. But the chart on the right shows a too-specific model that will not be able to guess the trend.
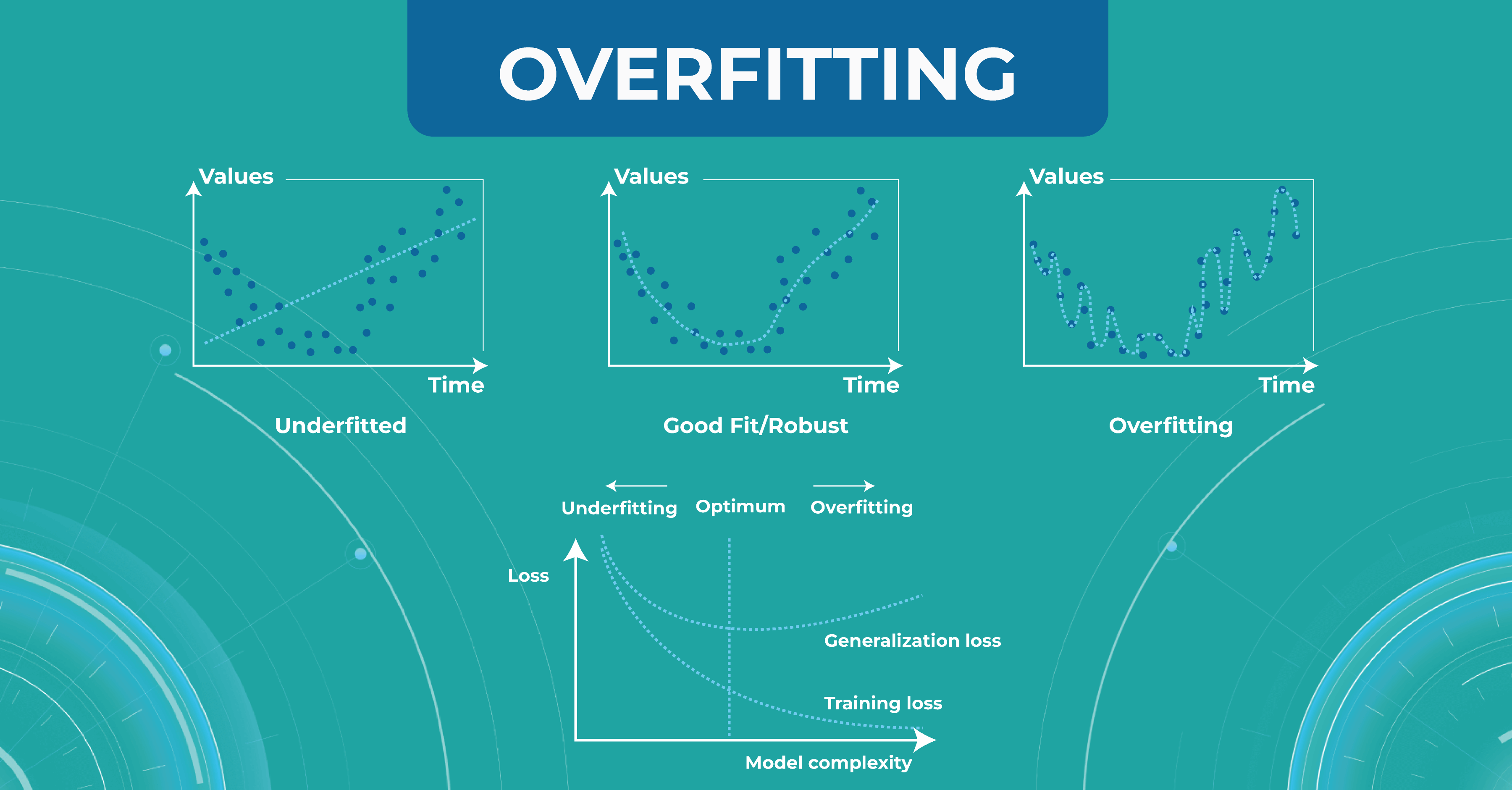
Another problem to solve is underfitting. This problem arises when we have chosen a model that is not complex enough to describe the trend in the data (left chart).
Bias variance trade-off
Another important concept we use in machine learning model validation is the bias variance trade-off. We want our models to always make accurate predictions and have no ground truth scattered. As shown at first/second circle.
However, there are situations when we have a model that predicts something close to the target, but from dataset to dataset, it has a strong scatter. This is showcased in the second circle.
In circle three, you can observe a situation where the model has heap predictions on different datasets, but they are inaccurate. This situation usually indicates that we need to almost entirely rebuild the model.

Overfitting and bias variance trade-off are very important in working with the model, as they allow us to track errors and select a model that will balance between spread and hitting the target.
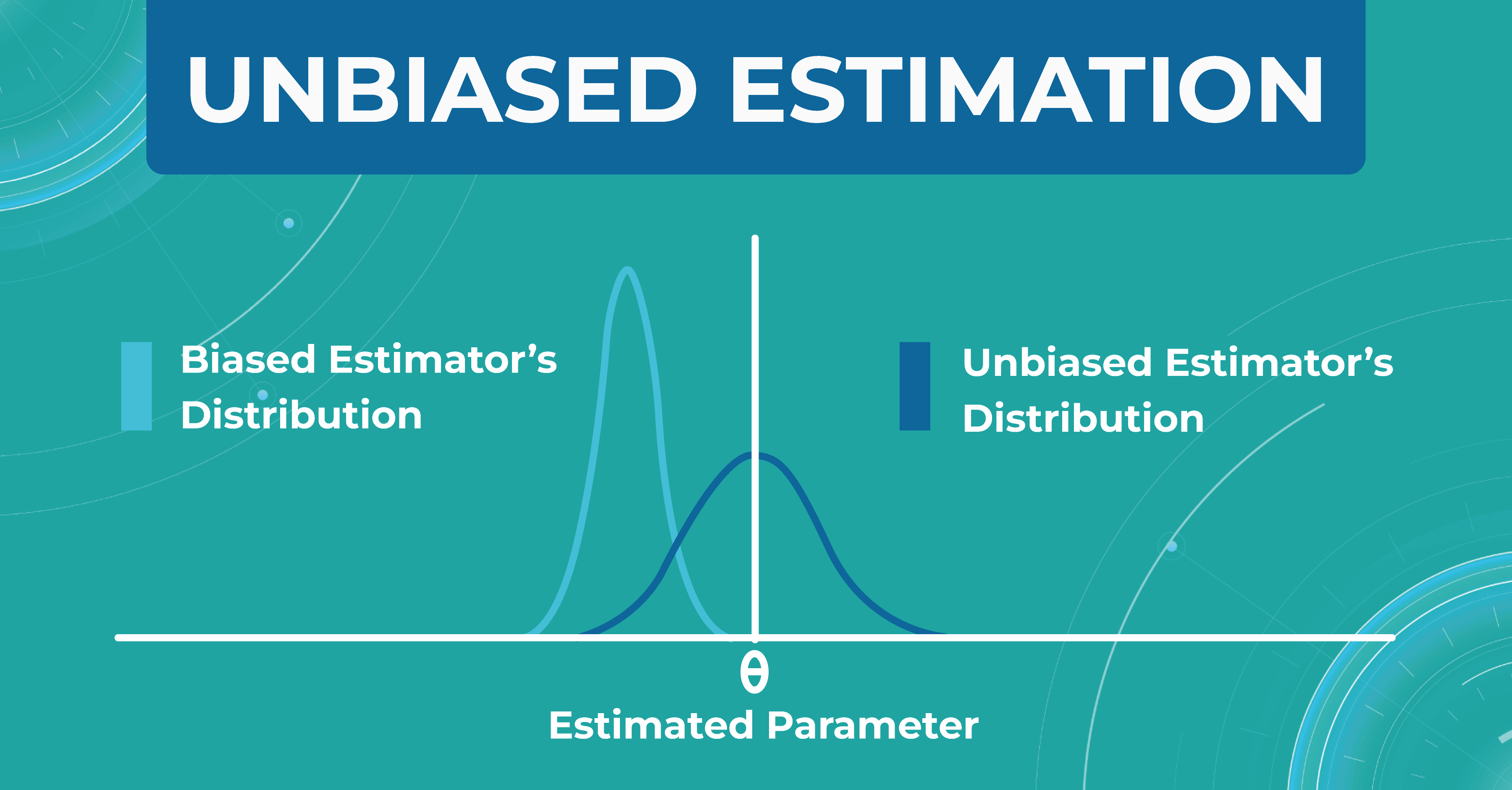
Unbiased estimation
In addition, within each model, we evaluate a set of parameters. We made a certain estimate (graph on the left), but in real life, the distribution of parameters differs (graph on the right). Thus, seeing that our estimate turned out to be shifted, we find another problem that needs to be solved. Machine learning in ophthalmology needs to make the estimate as unbiased as possible.
How do we validate the Altris AI model?
There are three main steps in choosing a validation strategy for machine learning in ophthalmology:
- we got familiar with ophthalmology, understood the nature of data, and where the leakages are possible;
- We estimated the dataset size and target distribution;
- understood the model’s training complexity (amount of operations/ number of parameters/ time) to pick the validation algorithms.
After that, we have a reliable strategy for the machine learning model validation. Here are some fundamental concepts we use in the validation of models’ performance.
Train/test split
Train/test split is the most simple and basic strategy that we use to evaluate the model quality. This strategy splits the data into train and test and is used on small datasets. For example, we have a dataset of 1000 pictures, 700 of which we leave for training and 300 we take for the test.
This method is good enough for prototyping. However, we don’t have enough datasets with it to do a simple double-check. This phenomenon is called high sampling bias: this happens when we encounter some kind of systematic error that did not fit into the distribution in the train or test.
By dividing data into train and test, we are trying to simulate how the model works in the real world. But if we randomly split the data into train and test, our test sample will be far from the real one. This can be corrected by constructing several test samples from the number of data we have and examining the model performance.
Train/test/holdout set
We leave the holdout as the final validation and use the train and test to work with the medical imaging machine learning model. After optimizing our model on the train/test split, we can check if we didn’t overfit it by validating our holdout set.

Using a holdout as a final sample helps us look at multiple test data distributions and see how much the models will differ.
K-fold cross validation
There is also a more general approach that Altris AI team use for validation — k-fold cross validation. This method divides all of our data equally into train and test.

We take the first part of the data and declare it as a test, then the second, and so on. Thus, we can train the model on each such division and see how it performs. We look at the variance and standard deviation of the resulting folds as it will give information about the stability of the model across different data inputs.
Do we need ML models to perform on par with doctors?
Here I will try to answer a question that worries many ophthalmologists and optometrists: can machine learning for medical image analysis surpasses an eye care specialist in assessing quality?
In the diagram below, I have drawn an asymptote called the Best possible accuracy that can be achieved in solving a particular problem. We also have a Human level performance (HLP), which represents how a person can solve this problem.
HLP is the benchmark that the ML model strives for. Unlike the Best possible accuracy, for which there is no formula, HLP can be easily calculated. Therefore, we assume that if a model crosses the human quality level, we have already achieved the best possible quality for that model. Accordingly, we can try to approximate the Best possible accuracy with the HLP metric. And depending on this, we understand whether our model performs better or worse.
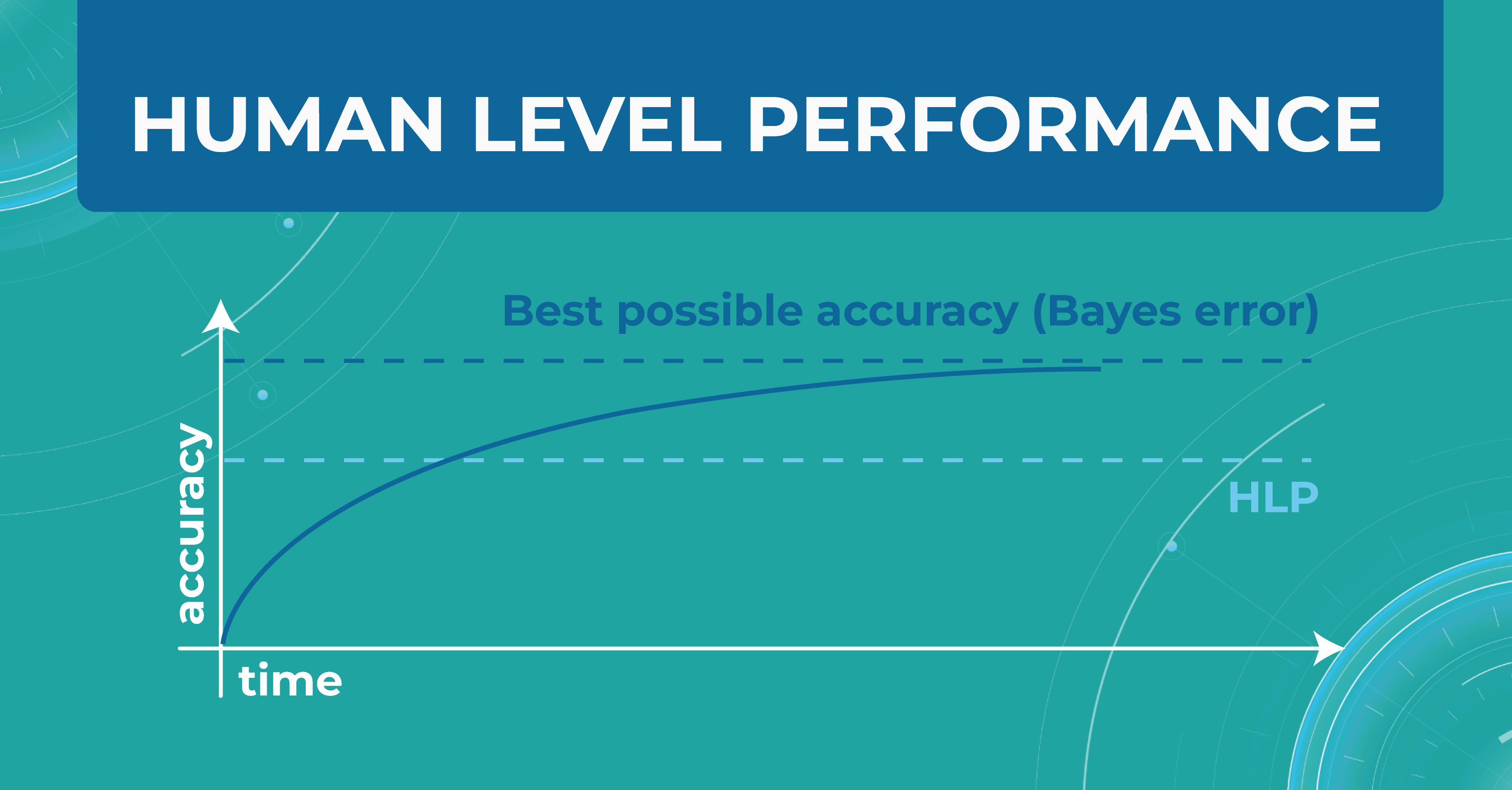
For those tasks that people do better and the ML model does worse, we do the following:
- collect more data
- run manual error analysis
- do better bias/variance analysis
But when the model crosses the HLP quality level, it is not entirely clear what to do next with the model and how to evaluate it further. So, in reality, we don’t need the model to outperform a human in interpreting images. We simply won’t know how to judge the quality of this model and whether it can be 100% objective and unbiased.
Avoidable bias
Let’s say we need to build a classifier for diabetic retinopathy based on OCT scans, and we have a control dataset prepared by people. In the first case, doctors are wrong 5% of the time. At the same time, the model on the train set is wrong in 10% of cases and on the test set — in 13%.

The difference between the model’s and the human’s performance is usually taken as the minimum difference between the train/test set and the human. In our case, it is 5% gap (10% – 5%) of avoidable bias. It is called avoidable bias because it can be fixed theoretically. In such a case, we need to take a more complex model and more data to better train the model.
In the second case, doctors determine the disease with a 9% error. If the model defines a disease with the same rates as the previous example, then the difference between the train/test set and the human will be 1% (10% – 9%), which is much better than avoidable bias.
Looking at these two cases, we must choose a strategy that will lower the variance for the machine learning model so that it works stably on different test sets. Thus, taking into account the avoidable bias and the variance between the samples, we can build a strategy for training the model so that it could potentially outperform the HLP someday. However, do we need it now?
Understanding HLP
To better understand the HLP metric, let’s consider the task of determining dry AMD on OCT scans. We have a fixed dataset and 4 train sets, each one determining dry AMD with a specific accuracy:
- ML engineers – 20%
- ophthalmologists – 5%
- 2 ophthalmologists – 3%
- 2 ophthalmologists and 1 professor of ophthalmology – 2%

We take a result of 2% as the best HLP possible. To develop our model, we can choose the performances we strive to get. The 20% error result is irrelevant, so we discard this option. But the level of 1 doctor is enough for model version number 1 model. Thus, we are building a development strategy for model 1.
Summing up
Machine learning will revolutionize the eye care industry. It provides confidence and second opinion to eye care specialists in medical image analysis.
If you are looking for ways to use machine learning in your eye care practice, feel free to contact us. At Altris AI, we improve the diagnostic process for eye care practitioners by automating the detection of 54 pathological signs and 49 pathologies on OCT images.